Vision in Action
Learning Active Perception from Human Demonstrations
Haoyu Xiong
Xiaomeng Xu
Jimmy Wu
Yifan Hou
Jeannette Bohg
Shuran Song
CoRL 2025
Abstract: We present Vision in Action (ViA), an active perception system for bimanual robot manipulation. ViA learns task-relevant active perceptual strategies (e.g., searching, tracking, and focusing) directly from human demonstrations. On the hardware side, ViA employs a simple yet effective 6-DoF robotic neck to enable flexible, human-like head movements. To capture human active perception strategies, we design a VR-based teleoperation interface that creates a shared observation space between the robot and the human operator. To mitigate VR motion sickness caused by latency in the robot’s physical movements, the interface uses an intermediate 3D scene representation, enabling real-time view rendering on the operator side while asynchronously updating the scene with the robot’s latest observations. Together, these design elements enable the learning of robust visuomotor policies for three complex, multi-stage bimanual manipulation tasks involving visual occlusions, significantly outperforming baseline systems.
Why do we need Active Perception (a.k.a Robot Neck) ?
Visual occlusion presents a significant challenge in everyday manipulation tasks.
Perception is inherently active — we purposefully adjust our viewpoint to capture task-relevant visual information. In contrast, relying on a static view is often ineffective.
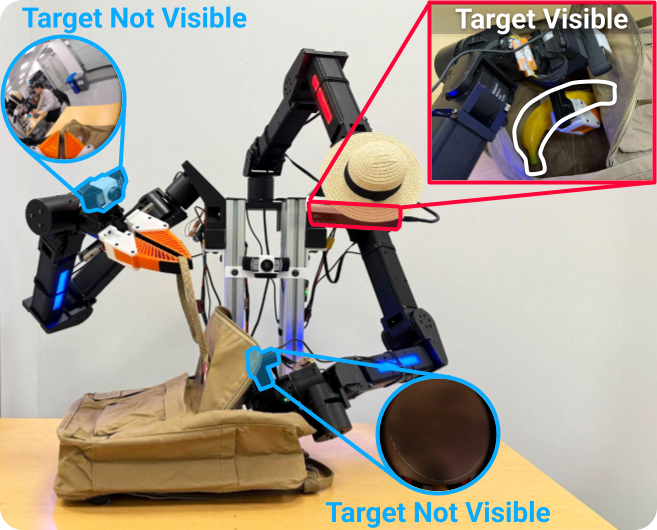
While robot wrist cameras can move with the arms, their motion is primarily dictated by manipulation needs, rather than being driven by perceptual objectives. The video below shows a failure case of a bimanual setup without a "robot neck".
The right wrist camera [R] is obstructed by the upper shelf tier, leading to insufficient visual cues for grasping. The chest camera [C] also fails to capture task-relevant information due to its fixed viewpoint, even when equipped with a fisheye lens.
Seeing what the robot sees
Many of today's data collection systems (e.g., the bimanual setup shown above) do not capture the rich perceptual behaviors of humans. This observation mismatch—between what the human sees and what the robot learns from—hinders the learning of effective policies.
VR teleoperation offers an intuitive way to collect data that captures human active perceptual behaviors. However, direct camera teleoperation approaches often introduce motion sickness 😵💫🥴🤢, due to motion-to-photon latency — the delay between a user's head movement and the corresponding visual update on the VR display. Additionally, robot teleoperation introduces control latency, which can come from the controller code, CAN communication, motor latency, etc. When users move their heads to teleoperate the robot's physical camera, there is a delay between receiving and executing the action command, causing the robot's camera pose to lag behind. The resulting mismatch in viewpoints between the human and robot leads to motion sickness.
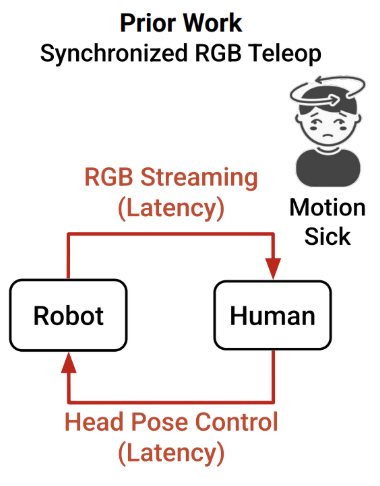
Our method — Async Teleop: Decoupled view rendering and asynchronous updating
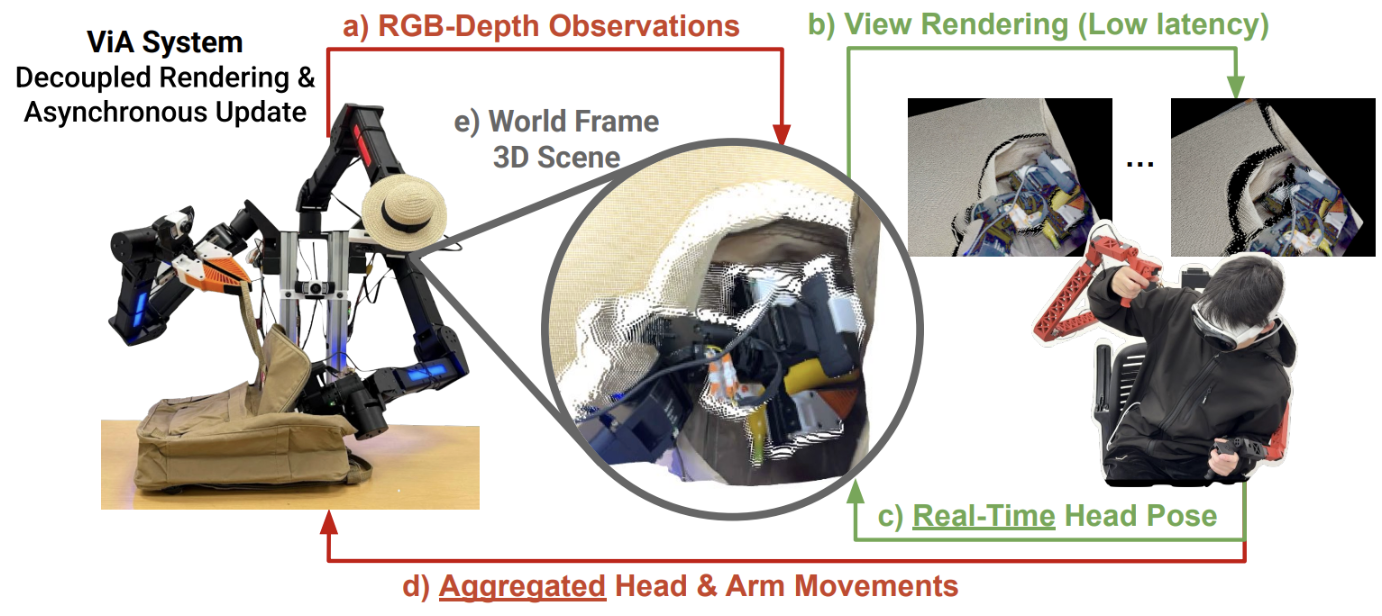
We decouple the user's view from the robot's view using a point cloud in the world frame, and we render stereo RGB images based on the user's latest head pose (the green loop). This allows the user's viewpoint to update instantly in response to user's head movements (via rendering), without waiting for the robot's camera to physically match the requested viewpoints. Asynchronously, (the red loop) we update the robot's head and arm pose using the user's head pose and the teaching arms' joint positions, and update the point cloud using the robot's new observations. The video below demonstrates teleoperation and the corresponding VR view. Check out our quickstart guide for async point cloud render.
Policy evaluation
We train a Diffusion Policy that predicts bimanual arm actions for manipulation and neck actions that mimic human active perceptual strategies, conditioned on visual and proprioceptive observations.
ViA uses a single active head camera (uncut rollouts) Evaluation results show that ViA (our method) enables the learning of robust visuomotor policies for three complex, multi-stage bimanual manipulation tasks.
What if we remove the robot neck? We compare ViA with the [Chest & Wrist Cameras] baseline (where the neck is omitted).
Findings: The [Chest & Wrist Cameras] baseline fails to provide sufficient task-relevant information. For example, the right wrist camera is completely occluded by the upper shelf tier during cup-grasping. In contrast, our method [ViA] enables the robot to dynamically adjust its camera viewpoint and gather more informative visual input, improving task performance.

Do reductant wrist cameras help? Compared to [ViA], the [Active Head & Wrist Cameras] setup includes additional wrist views as visual input. This comparison evaluates whether they provide additional useful information for policy learning.
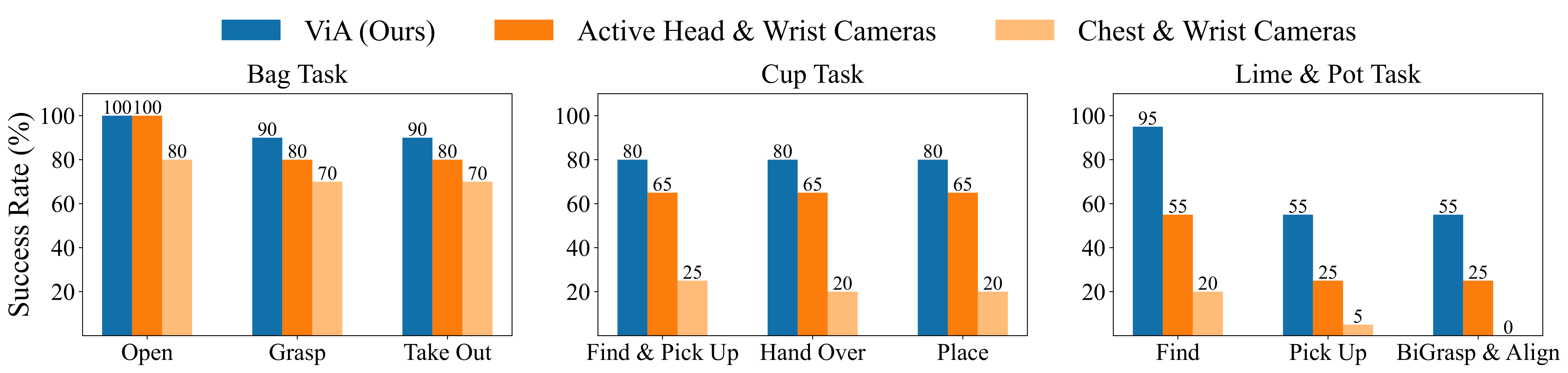
Findings: [ViA] consistently outperforms the alternative camera setups. Surprisingly, augmenting [ViA] with additional wrist camera observations ([Active Head & Wrist Cameras]) does not improve performance.
Visual representation matters
Intuitively, we expected that the world-frame point cloud could offer a robust spatial representation for the active camera setup. However, in the cup task, the [DP3] baseline often fails by directing the arm toward the empty section of the shelf, and failing to "find" the cup location. We hypothesize that this failure stems from [DP3] being trained from scratch, resulting in a lack of visual priors.
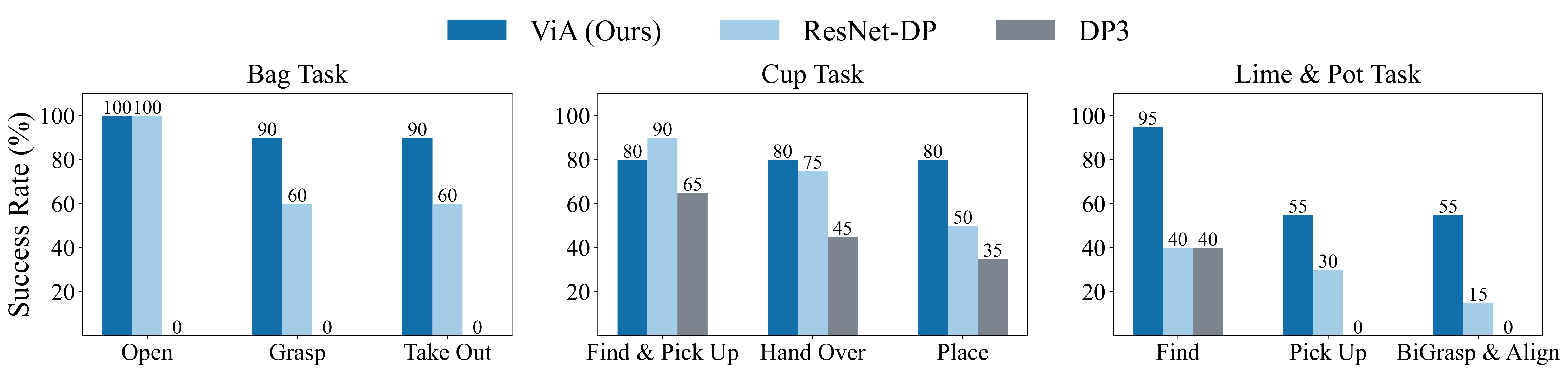
Findings: We found that the RGB policy performs reasonably well under active camera setups. Compared to the two baselines, [ViA] benefits from stronger semantic visual understanding enabled by the DINOv2 backbone. This allows the policy to actively find the object first before initiating arm actions.
In the videos above, the lime is randomly placed and often not visible at first. [ViA] actively searches for it before choosing the appropriate arm to use for grasping. In the fifth video, the lime was initially occluded by the robot gripper, but the robot moved it aside and successfully located the lime (though it failed to grasp it).
FAQ
1) Why not just use a 360° camera?
While a wider field of view helps robot perception,
a 360° camera alone doesn't resolve the problem of visual occlusion.
For example, in the shelf task, mounting a fixed 360° camera on the robot head (without a neck) still fails to reveal objects hidden in cluttered scenes.
To overcome this, the camera must actively move and adjust its pose to gain better viewpoints.
2) Why use a 6-DoF neck?
Human active perception relies on coordinated movements of both the torso and neck to adjust head pose (not just the neck!).
On the hardware side, simply mounting a 2-DoF robot neck on a static torso offers only limited flexibility and cannot replicate the full range of human motion.
We employ a simple yet effective solution: using an off-the-shelf robot arm as the robot neck.
This 6-DoF neck design allows the robot to mimic whole-upper-body motions from humans while avoiding hardware complexity.
3) Why add additional teaching arms (GELLO)?
In our bag task, for example, demonstrators must significantly bend their torso to peek inside the bag, while simultaneously coordinating both arms to retrieve the object.
Empirically, we found that holding something in the hand helps users better coordinate their upper-body motions.
Alternatively, one can use the Vision Pro's hand tracking to control the robot arm via inverse kinematics.
4) What are the limitations of point cloud rendering?
One challenge is sensor noise, even with the relatively high-quality depth maps provided by the iPhone.
Additionally, our method's reliance on single-frame depth results in incomplete 3D scene reconstructions.
In the future, integrating 3D/4D models (e.g., dynamic Gaussian Splatting) could improve the framework.
One more thing
We found that our bimanual hardware setup can be easily mounted onto a mobile base. To support future research on active perception for mobile manipulation, we open source a simple mobile hardware design using the TidyBot++ mobile base.
Acknowledgments
This work was supported in part by the Toyota Research Institute, NSF awards #2143601, #2037101, and #2132519, the Sloan Foundation, Stanford Human-Centered AI Institute, and Intrinsic.
The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies, either expressed or implied, of the sponsors.
We would like to thank ARX for the ARX robot hardware.
We thank Yihuai Gao at Stanford for his help on the ARX robot arm controller SDK.
We thank Ge Yang at MIT and Xuxin Cheng at UCSD for their help and discussion of VR.
We thank Max Du, Haochen Shi, Han Zhang, Austin Patel, Zeyi Liu, Huy Ha, Mengda Xu,
Yunfan Jiang,
Ken Wang, and Yanjie Ze for their helpful discussions.
We sincerely thank all the volunteers who participated in and supported our user study.
BibTeX
@article{xiong2025via,
title = {Vision in Action: Learning Active Perception from Human Demonstrations},
author = {Haoyu Xiong and Xiaomeng Xu and Jimmy Wu and Yifan Hou and Jeannette Bohg and Shuran Song},
journal = {arXiv preprint arXiv:2506.15666},
year = {2025}
}